functionclickLogin() { var userName=$("#userName").val(); var password=$("#password").val(); var data={}; data['number']=userName; data['password']=password; var result=transfer("/text_project/login",data); if(result[0]=='200'){ window.location.href="/text_project/main"; } else{ console.log("error"); } }
A linear collection that supports element insertion and removal at both ends. The name deque is short for “double ended queue” and is usually pronounced “deck”. Most Deque implementations place no fixed limits on the number of elements they may contain, but this interface supports capacity-restricted deques as well as those with no fixed size limit.
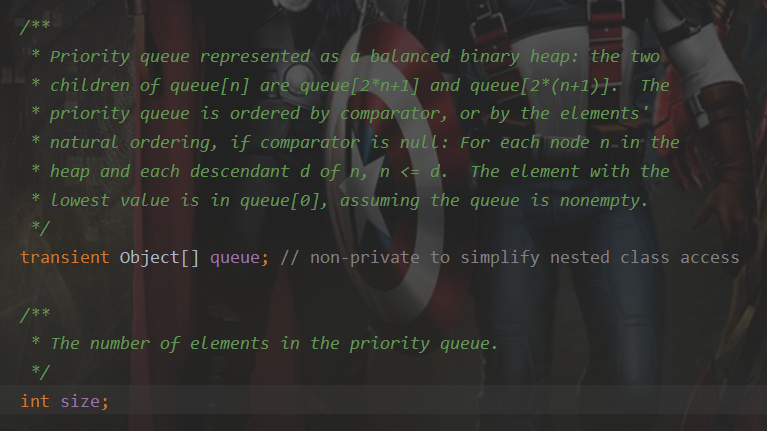
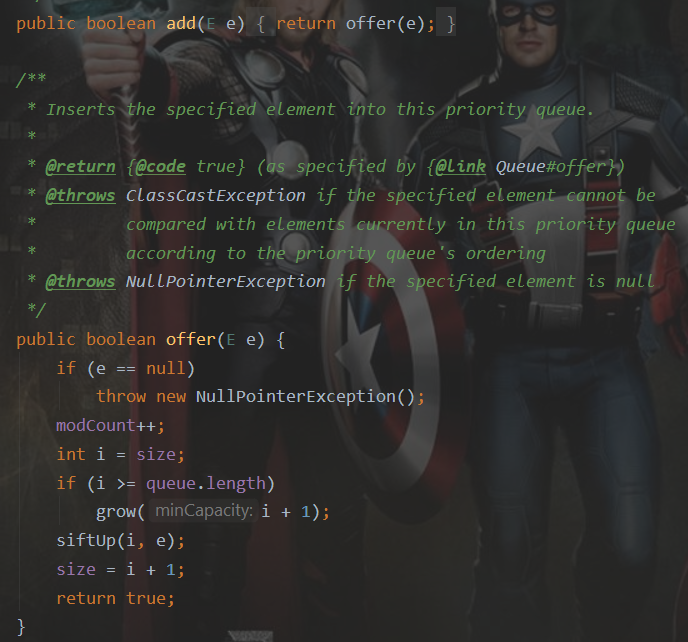
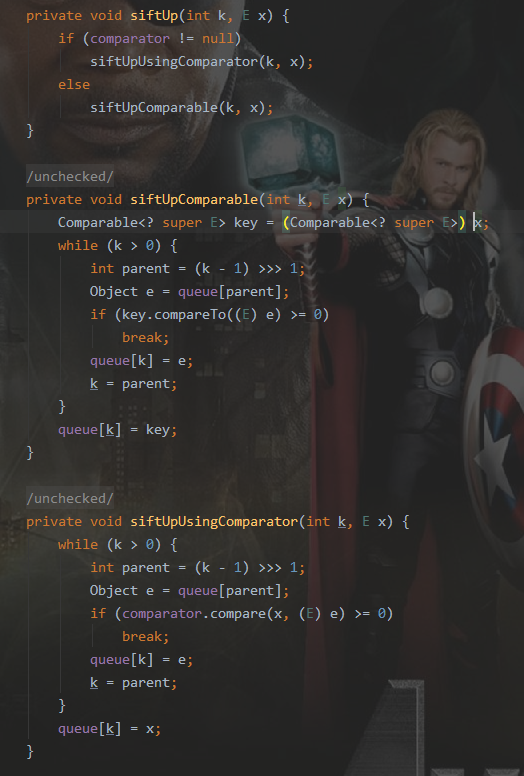
A collection designed for holding elements prior to processing. Besides basic Collection operations, queues provide additional insertion, extraction, and inspection operations. Each of these methods exists in two forms: one throws an exception if the operation fails, the other returns a special value (either null or false, depending on the operation). The latter form of the insert operation is designed specifically for use with capacity-restricted Queue implementations; in most implementations, insert operations cannot fail.
publicstaticvoidmain(String[] args){ Name name1=newName(); name1.setName("name1"); Text t1=newText(); t1.setAge(12); t1.setName(name1); Text t2=(Text) t1.clone(); System.out.println(t2.getName().getName()); name1.setName("name2"); System.out.println(t2.getName().getName());