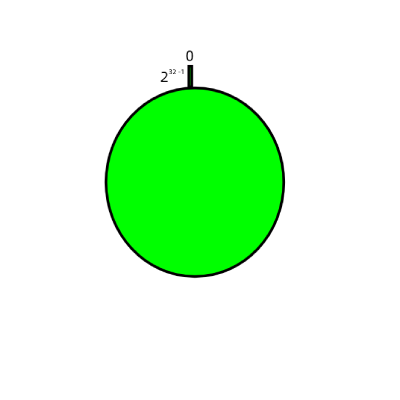
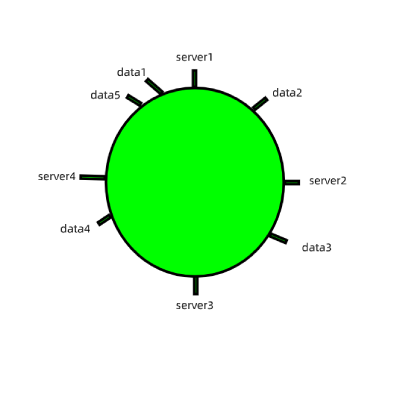
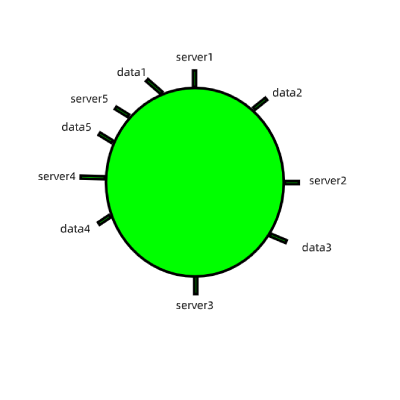
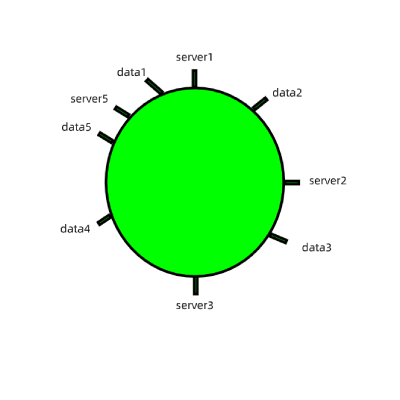
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
| package org.CommonAlgorithms.ConsistentHash;
import org.CommonAlgorithms.HashAlgorithm.HashService;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
public class ConsistentHashingImpl implements ConsistentHashing {
private static final Logger log = LoggerFactory.getLogger(ConsistentHashingImpl.class);
private static final String virtualNodeFormat = "%s&&%d";
private SortedMap<String, List<String>> realNodeToVirtualNode;
private SortedMap<Integer, String> hashToNodes;
private Map<String, List<String>> nodeToData;
private int virtualNodeNum;
private HashService hashService;
public ConsistentHashingImpl() {
this(0, new String[0]);
}
public ConsistentHashingImpl(String... nodes) {
this(0, nodes);
}
public ConsistentHashingImpl(int virtualNodeNum) {
this(virtualNodeNum, new String[0]);
}
public ConsistentHashingImpl(int virtualNodeNum, String... nodes) {
if(virtualNodeNum < 0){
log.error("virtual num is not allow smaller than 0");
throw new IllegalArgumentException();
}
this.virtualNodeNum = virtualNodeNum;
realNodeToVirtualNode = new TreeMap<>();
hashToNodes = new TreeMap<>();
nodeToData = new HashMap<>();
for(String server : nodes){
hashToNodes.put(getHash(server), server);
nodeToData.put(server, new LinkedList<>());
}
if(virtualNodeNum > 0){
for(String server : nodes){
addVirtualNode(server);
}
}
}
@Override
public boolean putData(List<String> data) {
for(String incomingData : data){
if(!putData(incomingData)){
return false;
}
}
return true;
}
@Override
public boolean putData(String data) {
if(hashToNodes.isEmpty()){
log.error("put data, usable server is empty");
return false;
}
int currentHash = getHash(data);
SortedMap<Integer, String> usableNodes = hashToNodes.tailMap(currentHash);
String node = usableNodes.isEmpty() ? hashToNodes.get(hashToNodes.firstKey()) : usableNodes.get(usableNodes.firstKey());
List<String> dataList = nodeToData.get(node);
dataList.add(data);
log.info("put data, data {} is placed to server {}, hash: {}", data, node, currentHash);
return true;
}
@Override
public boolean removeNode(String node) {
int removeServerHash = getHash(node);
if(!hashToNodes.containsKey(removeServerHash)){
log.error("remove server, current server is not in server list, please check server ip");
return false;
}
List<String> removeServerData = nodeToData.get(node);
if(virtualNodeNum != 0){
for(String virtualNode : realNodeToVirtualNode.get(node)){
removeServerData.addAll(nodeToData.get(virtualNode));
hashToNodes.remove(getHash(virtualNode));
nodeToData.remove(virtualNode);
}
}
hashToNodes.remove(removeServerHash);
nodeToData.remove(node);
if(hashToNodes.size() == 0){
log.info("remove server, after remove, server list is empty");
return true;
}
putData(removeServerData);
log.info("remove server, remove server {} success", node);
return true;
}
@Override
public boolean addNode(String node) {
int addServerHash = getHash(node);
if(hashToNodes.isEmpty()){
hashToNodes.put(addServerHash, node);
nodeToData.put(node, new LinkedList<>());
if(virtualNodeNum > 0){
addVirtualNode(node);
}
} else{
SortedMap<Integer, String> greatServers = hashToNodes.tailMap(addServerHash);
String greatServer = greatServers.isEmpty() ? hashToNodes.get(hashToNodes.firstKey()) : greatServers.get(greatServers.firstKey());
List<String> firstGreatServerData = new LinkedList<>(nodeToData.get(greatServer));
hashToNodes.put(addServerHash, node);
nodeToData.put(greatServer, new LinkedList<>());
nodeToData.put(node, new LinkedList<>());
if(virtualNodeNum != 0){
addVirtualNode(node);
}
putData(firstGreatServerData);
}
log.info("add server, server {} has been added", node);
return true;
}
@Override
public void printAllData() {
nodeToData.forEach((server, data) -> log.info("server {} contains data {}", server, data));
}
@Override
public void setHashMethod(HashService hashService) {
if(!hashToNodes.isEmpty()){
throw new UnsupportedOperationException();
}
this.hashService = hashService;
}
private void addVirtualNode(String realNode){
if(virtualNodeNum > 0){
List<String> virtualNodeList = new LinkedList<>();
for(int cnt = 0; cnt < this.virtualNodeNum; cnt++){
String virtualNodeName = String.format(virtualNodeFormat, realNode, cnt);
int virtualNodeHash = getHash(virtualNodeName);
if(hashToNodes.containsKey(virtualNodeHash)){
continue;
}
virtualNodeList.add(virtualNodeName);
hashToNodes.put(virtualNodeHash, virtualNodeName);
nodeToData.put(virtualNodeName, new LinkedList<>());
}
realNodeToVirtualNode.put(realNode, virtualNodeList);
}
}
private int getHash(String data){
return hashService == null ? defaultGetHash(data) : hashService.getHash(data);
}
private int defaultGetHash(String data){
int res = 0;
for(char tempChar : data.toCharArray()){
if(tempChar >= '0' && tempChar <= '9'){
res += tempChar;
}
}
return res;
}
}
|